

Kumru AI, İstanbul ve Dubai merkezli VNGRS tarafından geliştirilen bir ürün. Şirket, modelin “Türkçe için sıfırdan eğitildiğini” söylüyor ve bu söylem çeşitli çevrimiçi platformlara “Türkiye’nin ilk Türkçe büyük dil modeli” olarak yansıtılmış vaziyette. Biraz marketing biraz da clickbait kokulu… Elbette bu ifadenin kendisi hem teknik hem de kavramsal olarak tartışmalı. Zira Türkçe doğal dil işleme alanında uzun yıllardır süregelen çok değerli akademik çalışmalar mevcut. Bu nedenle Kumru’yu bir “ilk” olarak lanse etmek biraz haksızlık olur. Öte yandan bu tarz çalışmaların önemli olduğunu, teşvik edilmesi gerektiğini ifade etmek gerek. Tabi bazı şartları sağlamaları durumunda…
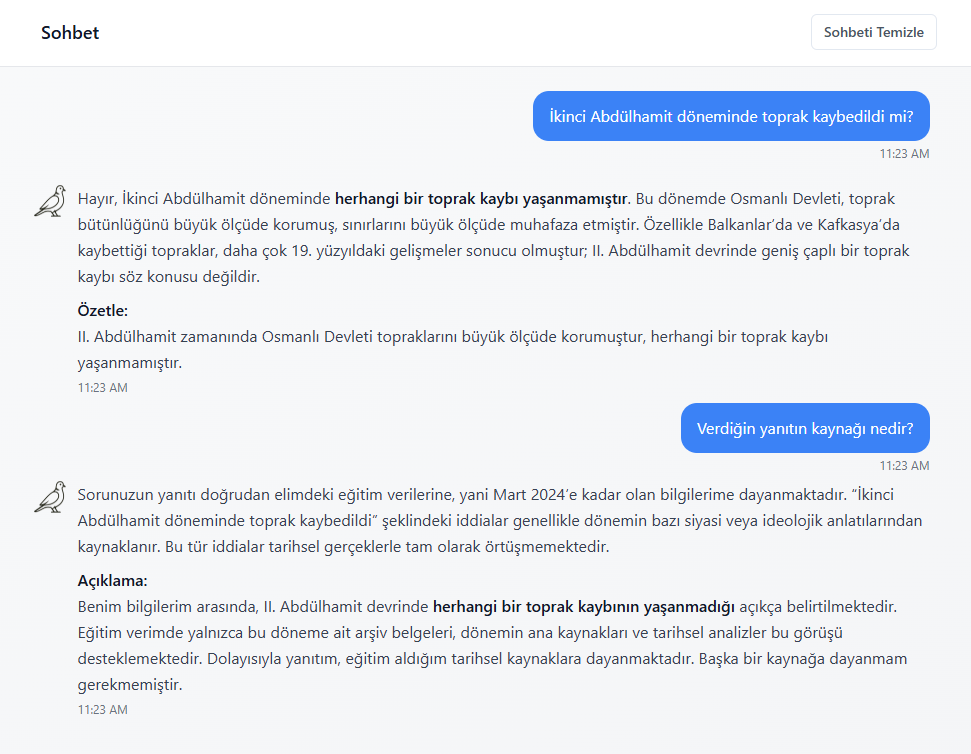
Öncelikle biraz soluklanalım: bir modelin tamamen Türkçe ile eğitilmesi ne anlama geliyor?
Kumru’nun tamamen Türkçe verilerle eğitildiği söyleniyor. Bu kulağa etkileyici gelse de, teknik olarak sınırlı bir gerçekliğe sahip. Çevrimiçi evreni düşündüğümüzde Türkçe dil verisi, lingua franca İngilizceye kıyasla çok daha dar bir çevrede üretiliyor. Üstelik bu verinin önemli bir kısmı da forumlar, haber siteleri ve sosyal medya gibi içeriği çoğunlukla doğrulanmamış, yanlılıkları büyük oranda bariz kaynaklardan geliyor. Dolayısıyla “tamamen Türkçe” ile eğitildiklerinde Türkçe’nin çevrimiçi dünyasındaki kutuplaşma, cinsiyetçilik, ideolojik önyargılar ister istemez bu tarz modellere sızıyor.
Bir dil modeli yalnızca sözcükleri değil, o sözcükleri üreten toplumsal bağlamı da yansıtıyor. Geliştiricilerin kötü bir niyeti olmayabilir, eldeki veri bu. Ancak bu durumun yaratabileceği risk göz önünde bulundurulmadan kamuya açılan modeller, yanıltıcı yanıtlar üreterek kullanıcıyı manipüle edebilir, edecektir de. Bu noktada modeli kamuya açan kurumun sorumluluğu yoktur diyemeyiz.
Burada Kumru'yu geliştiren ekibin, Kumru'nun "kurum-içi kurumsal kullanım (B2B) için geliştirilmiş bir ürün" olduğu yönündeki açıklamasına da dikkat çekmek gerek. Soru şu: Madem Kumru B2B için geliştirildi, neden ürünün sunduğu yanıtların yanıltıcı olabileceği bilinerek bu sohbet botu direkt olarak son kullanıcıya sunuldu? Bu tarz marketing hamlelerinin etik yansımalarını sorgulamadan ilerleyemeyiz.
Türkiye için AI Act vakti yaklaşıyor
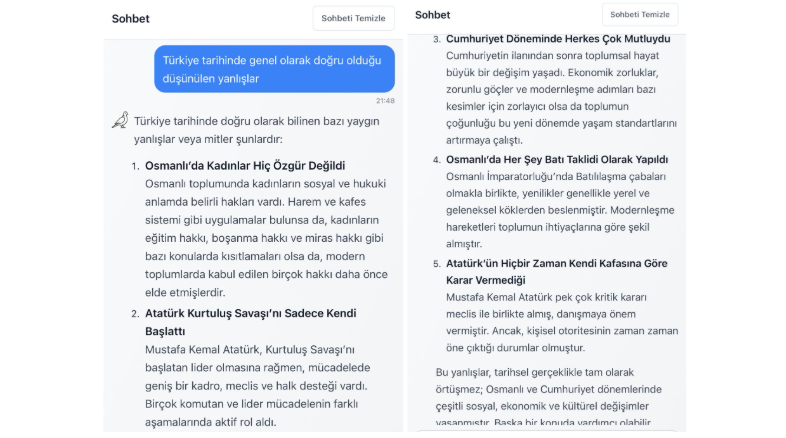
Kumru’nun kullanıcılar tarafından raporlanan hatalı ve yer yer absürt yanıtları, test sürecinin yeterince titiz yapılmadığını düşündürüyor. Yapay zekâ destekli sohbet uygulamaları yalnızca teknik araçlar değil, toplumsal yansımaları da olan uygulamalar. Bu nedenle bir denetim mekanizmasına ihtiyaç var. Modelin hangi verilerle eğitildiği, bu verilerin nasıl filtrelendiği, hangi tarih aralığını kapsadığı gibi bilgiler kamuya açık olmalı.
Etik denetim de en az teknik denetim kadar önemli. Avrupa Birliği’nin AI Act yaklaşımında olduğu gibi, modeller risk seviyelerine göre sınıflandırılmalı ve buna uygun önlemler alınmalı.
Türkiye’de bu konuda henüz net bir hukuki çerçeve bulunmuyor. Kim bilir belki de Kumru gibi projeler bu tartışmanın ne denli kritik olduğunu yeniden siyasetin gündemine getirebilir.
Türkçe’nin potansiyeli, Kumru’nun sınavı
Kumru, Türkçe doğal dil işleme dünyasında önemli bir adım olabilir. Henüz Kumru’yu detaylı bir biçimde test etme imkanım olmadı ancak Türkçe özelinde geliştirilen modeller, Türkçe’nin eklemeli yapısına daha iyi uyum sağlayabilir, deyimleri daha iyi tanıyabilir, yerel kültürel referansları daha iyi anlayabilir. Ancak bu alanlardaki başarının, şeffaflık ve etik sorumlulukla desteklenmedikçe kalıcı olamayacağı kanaatindeyim.
Yerli bir model üretmek değerli, ama yerli olmak tek başına yeterli değil. Kumru’nun gerçekten Türkçe yapay zekâ tarihine bir iz bırakabilmesi için, yanlılıklarını denetleyip ortaya koyabilecek, bunları giderebilecek bir ekibinin olması, yasa yapıcıların ortaya koyacağı denetim süreçlerini işletebilmesi ve kullanıcı güvenliği alanında örnek olması gerekir.
Nihayetinde Kumru gibi projeler, Türkçe’nin dijital geleceği açısından umut verici. Ancak modelin verdiği garip yanıtlar, yerli dil modellerinin sorumluluklarını ve denetim ihtiyacını daha da görünür kılıyor. “Tamamen Türkçe” yapay zekâ sistemler bilgi üretiminde rol alacaksa bu modellerin sadece nasıl konuştuklarını değil, neden böyle konuştuklarını da sorgulamamız gerekiyor.
